
Applied Capstone Project – IBM DataScience
By S, Dharshan
This Article is part of the IBM Data science capstone project. We saw how data science was used to cluster data into different clusters using different algorithms such as K-means. Today we are going to apply the model to real-world data. Here we are going to take location data from different areas in Chennai and use that data to conclude which area is suitable to open a particular type of Restaurant.
To checkout my notebook code at GitHub , Click Here
Introduction
Chennai AKA Madras (the official name until 1996), is the capital of the Indian state of Tamil Nadu. Located on the Coromandel Coast off the Bay of Bengal, it is one of the largest cultural, economic and educational centers of south India. According to the 2011 Indian census, it is the sixth-most populous city and fourth-most populous urban agglomeration in India. The city together with the adjoining regions constitutes the Chennai Metropolitan Area, which is the 36th-largest urban area by population in the world.
Great tourist attraction
The traditional and de facto gateway of South India, Chennai is among the most visited Indian cities by foreign tourists. It was ranked the 43rd-most visited city in the world for the year 2015. The Quality of Living Survey rated Chennai as the safest city in India. Chennai attracts 45 percent of health tourists visiting India and 30 to 40 percent of domestic health tourists. As such, it is termed “India’s health capital”.Chennai has the fifth-largest urban economy in India. This gives us additional reasons to open restaurants in this great city
Problem Statement
Opening a restaurant is a lot of commitment and investors need to assess the risk factors before investing in the business. In this project, I’m going to analyze restaurant venues present in the different areas of Chennai and predict which location would be most suitable to open our restaurant
Data Source
Web Scrapping is an easy way to get real-world data from publicly available sources like Wikipedia. For our analysis, I web scrap data from a list of areas in the Chennai Wikipedia page and used that to create a data frame for further analysis. Here below is attached to the table from which data is scrapped.
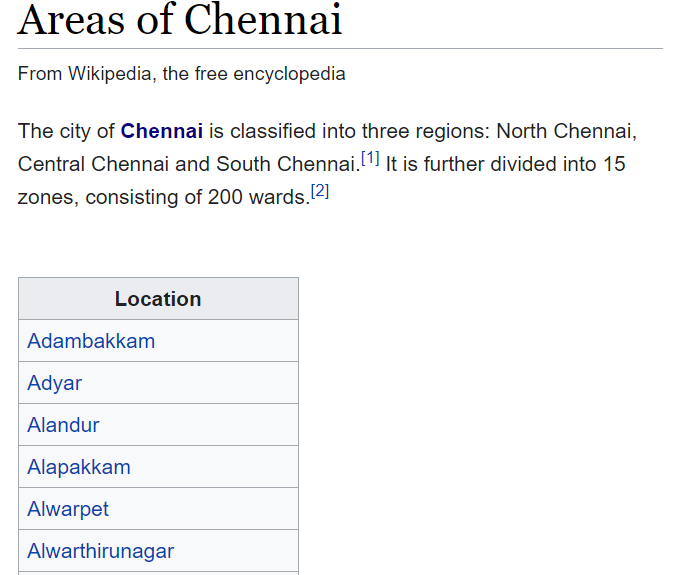
Data preprocessing
Cleaning from Wikipedia
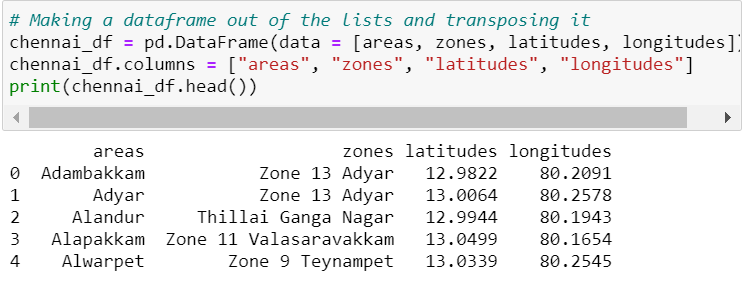
The data source is not clean and also we couldn’t get the zone name for respective areas. So we got all 161 areas from the city of Chennai and then we used geopy to get zone names for areas and added them to the data frame. Preprocessing data can be done manually but takes much time. writing own python scripts to clean data will be really helpful in the process.
Adding Lat, Long using Geopy
We use Geopy python lib to add receive location data for particular areas. Geopy is a Python client for several popular geocoding web services. geopy makes it easy for Python developers to locate the coordinates of addresses, cities, countries, and landmarks across the globe using third-party geocoders and other data sources.
We added location data based on area name and we created a data frame using all the data. We can check the data frame head below. Click here to check out Geopy
Locations on Map
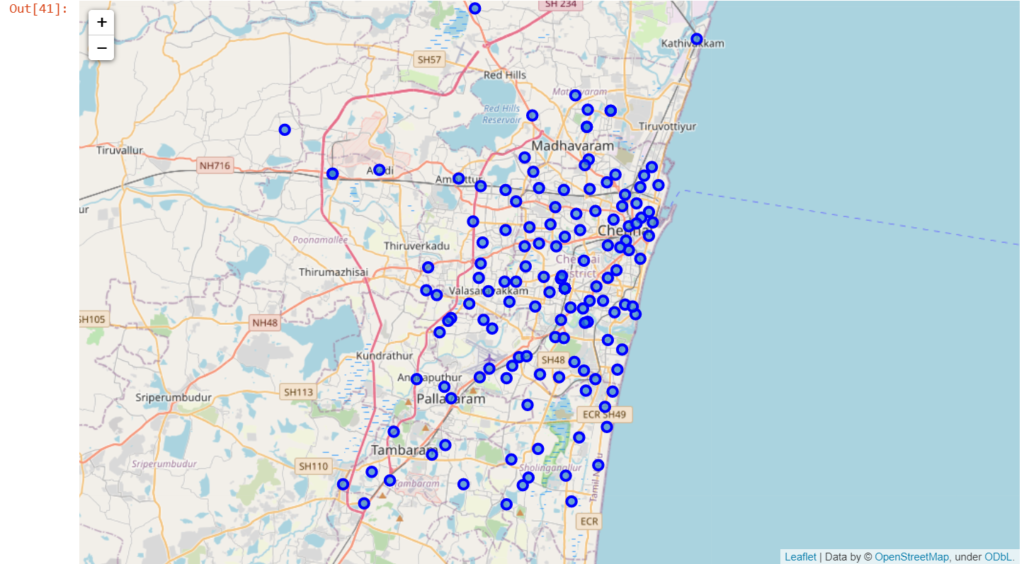
Getting Venues using Folium API
The next thing is to get the data regarding the venues’ using the Foursquare API. We would collect data corresponding to venues present in a radius of 500 meters from each area. Also, we would limit the number of results returned to 100 per area.
We create a new data frame to put this data in, along with some of the relevant data from the previous one.
Grouping this data by areas and calculating the means(average occurrences) of the venue categories for each area provides us with information regarding the presence of venue categories by areas.
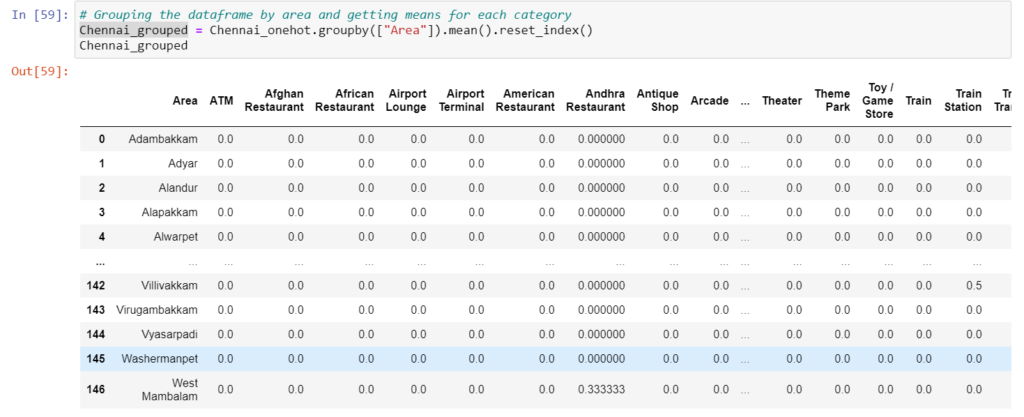
Too Many Different Venues
Our grouped venue data frame has too many columns. Here we are going to filter out restaurants alone from other types of venues. Then we will choose our venue based on the frequency of occurrence.
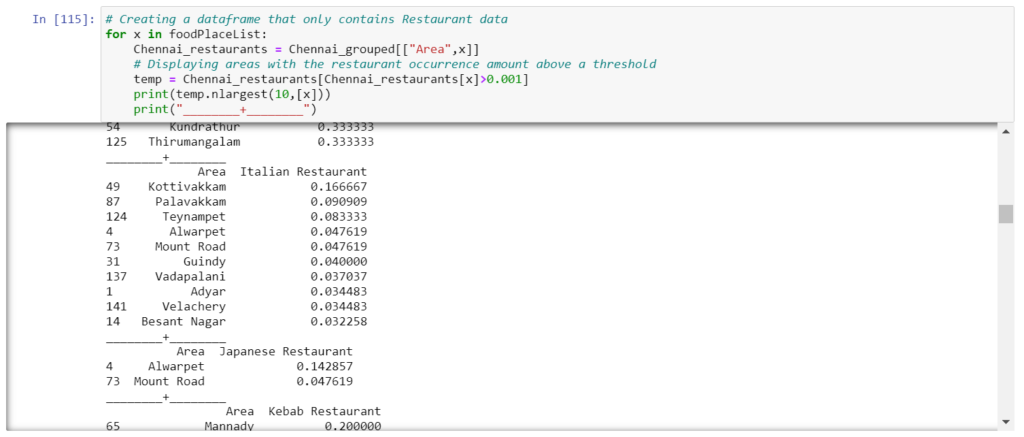
Decision to open Italian Restaurant
As we can see Italian restaurants are exotic places which are found in various parts of neighborhoods. So for our report, we are going with Italian Restaurants as they have a better chance of surviving in the city and also being exotic enough to attract many tourists to come to visit the place
Clustering using K-Means algorithm
We will cluster the areas according to the measure of occurrences of restaurants in them. For determining the optimal number of clusters, we need to plot the performances(inertia) against the range of values of ‘K’ and then select the number for performing the Clustering
k-means clustering is a method of vector quantization, originally from signal processing, that aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean (cluster centers or cluster centroid), serving as a prototype of the cluster.
We perform K-Means clustering with values for K from one through ten to find the optimal ‘K’ using the elbow method, which in our case is four.

Color Coding the Venues based on Cluster Label
We segregate the venues into four clusters and add the cluster labels to our final data frame. We examine the clusters by plotting them onto a map. Each color code represents the level of concentration of Italian restaurant present in that particular area
Following are the color codes for each cluster:
- Cluster 0: Green – Least
- Cluster 1: Violet – High
- Cluster 2: Yellow – Moderate
- Cluster 3: Grey – Very high
Lets Check out the map with concentration of Italian restaurant.
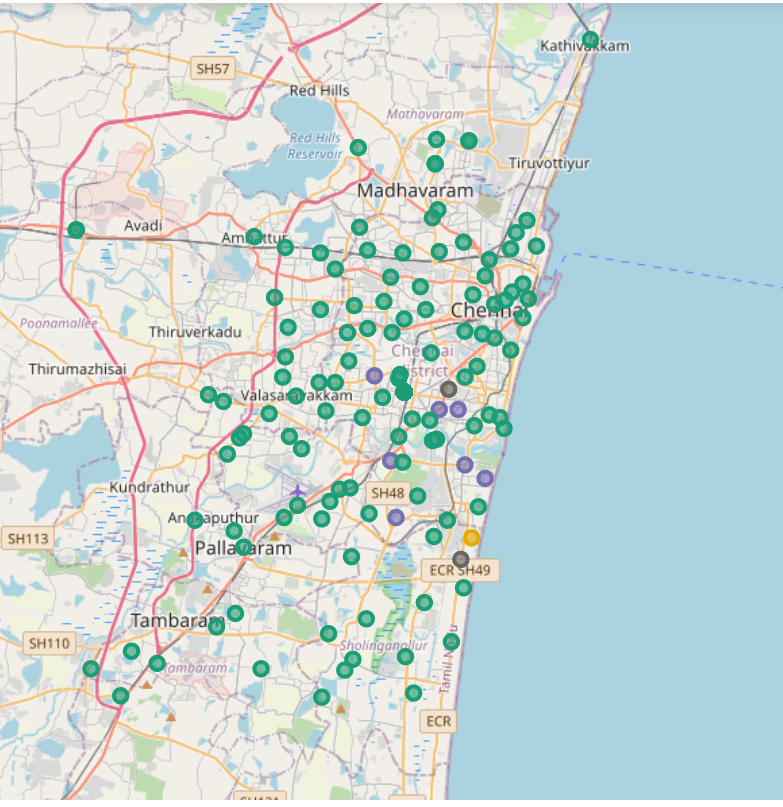
Cluster Analysis
Cluster 0 has the least number of Italian restaurants and so there is no competition. But also there’s a risk of having no customers in the surrounding neighborhood who likes to have Italian cuisine and might be the reason why there is the least concentration.
Clusters 2 has a moderate concentration of Italian restaurants. Property developers with unique selling propositions to stand out from the competition can also open new restaurants in neighborhoods in clusters 2 with moderate to high competition.
Lastly, restaurants in cluster 3 and cluster 1are probably suffering from strong competition due to oversupply and high concentration of restaurants. Hence, Property developers are advised to avoid neighborhoods in these which already have a high concentration of restaurants and are suffering from intense competition.
Conclusion
We got the winner : Kottivakkam
Kottivakkam belongs to cluster 2 which has a moderate concentration of Italian restaurants. The area is near the beach and surrounded by many tourist attractions. So I am coming to the conclusion that we should choose yellow as are cluster.
We might ask why to go for a moderately concentrated place instead of going to areas where no Italian Restaurants are found. The reason for this is people in the green areas may not prefer Italian restaurants and may not be even aware of Italian cuisines. Also, people in the grey areas will have too many Italian restaurants to choose from and our entity may go unnoticed during the process.
Our targeted location is surrounded by places where a high concentration of Italian restaurants present in the area but in kottivakam the concentration is moderate. This strategy is based on the Nash equilibrium.